开篇:为什么2026年你离不开阅读论文AI助手?
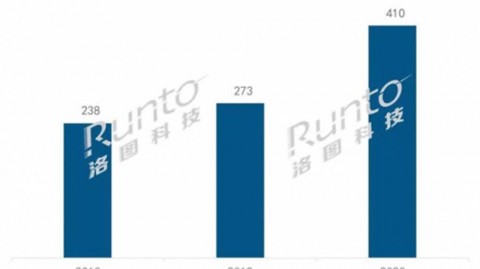
2026年,学术界正在经历一场静默而深刻的效率革命。AI助手正以前所未有的速度渗透科研工作流的每一个环节——从文献综述到数据清洗,从实验记录到论文排版-1。根据行业研究数据,人工智能文学理解工具市场在2025年已达到约6.89亿美元规模,预计2026年将增长至8.18亿美元,复合年增长率高达22.44%-。

许多刚接触AI文献工具的读者常常面临这样的困境:只知道上传PDF让AI“读一遍”,却不懂得如何精准提问获取深层信息;听说过ChatPDF、NotebookLM、Perplexity这些名词,却不清楚它们之间的差异和各自的适用场景;面对学术论文中的复杂表格、公式和图表时,AI助手为何常常“答非所问”,背后的技术瓶颈在哪里。
本篇将从痛点切入 → 核心概念 → 关联技术 → 代码示例 → 底层原理 → 面试考点这一完整链路,系统拆解阅读论文AI助手的运作机制与应用实战,帮助你既“会用”又“懂原理”。
一、痛点切入:传统论文阅读的困境与AI助手的破局
让我们先看一个真实场景。假设你是一名计算机领域的研究生,需要在两周内完成一篇关于“大模型检索增强生成”的文献综述。传统的做法是:
打开Google Scholar或arXiv,输入关键词“Retrieval-Augmented Generation”
面对成百上千篇论文,逐个打开PDF阅读摘要
读到感兴趣的论文后,通读全文,手动摘录核心观点
遇到不熟悉的专业术语,需要额外查阅资料
读完一篇后记不住关键信息,不得不反复回看
最后手动整理成文献笔记,标注引用来源
传统方式的痛点十分明显:
效率低下:一篇复杂论文可能需要数小时才能消化核心思想-37
信息过载:传统的关键词常产生两个极端——结果过于零散或信息过量-53
读后即忘:浏览了数十个文献分页,却记不清哪个观点出自哪篇文章,陷入“金鱼脑”困境-53
引用验证困难:AI生成的回答如果无法追溯原文,学术严谨性无从保障
格式壁垒:扫描件PDF、复杂表格、数学公式往往成为AI理解论文的“拦路虎”
正是在这样的背景下,阅读论文AI助手应运而生。这类工具的核心设计初衷是:将研究者从机械式的数据提取中解放出来,从单篇的“垂直阅读”转向跨论文的“水平综述”,实现文献处理效率的量级提升-53。
二、核心概念:RAG——检索增强生成
RAG(Retrieval-Augmented Generation,检索增强生成) 是当前阅读论文AI助手最核心的底层技术架构。
标准定义
RAG是一种将信息检索与大语言模型生成能力相结合的技术范式。其基本流程是:当用户提出问题时,系统首先从知识库中检索相关文档片段,然后将这些片段作为“上下文”提供给大模型,最终生成带有事实依据的回答。
关键词拆解
检索(Retrieval) :从论文库中与问题最相关的内容片段,确保回答有据可查
增强(Augmented) :将检索到的内容注入到提示词中,为大模型提供“知识外挂”
生成(Generation) :基于检索到的上下文,大模型生成自然语言答案
生活化类比
想象你在考试——如果你只知道“死记硬背”书本内容(单纯的大模型),遇到没见过的题目就可能答不出来;但如果允许你翻书查资料(检索),把相关知识点找出来再看(增强),你就能回答得更准确。RAG就像给大模型配了一本可以随时翻阅的“参考书”。
价值所在
RAG技术有效解决了大语言模型在学术专业领域的三大痛点:知识更新滞后(模型训练数据截止于某个时间点)、幻觉问题(编造不存在的文献或结论)以及无法追溯来源(回答缺乏可验证性)。基于RAG技术的AI助手能够确保输出的结论均有据可查-49。
一句话记忆:RAG = 先查资料再回答,让AI告别“胡说八道”。
三、关联概念:PDF文档解析
如果说RAG是AI论文阅读的“大脑”,那么PDF文档解析就是它的“眼睛”——没有高质量的前置解析,再聪明的模型也无法准确理解论文内容。
标准定义
PDF文档解析是指将PDF文件(尤其是扫描件或包含复杂排版的文件)中的文本、表格、公式、图表等元素提取出来,转换为大模型可处理的结构化数据的过程-69。
PDF解析 vs. RAG:思想与落地的关系
| 维度 | RAG | PDF文档解析 |
|---|---|---|
| 本质 | 技术思想/架构 | 具体实现手段 |
| 作用 | 定义“怎么问、怎么答” | 定义“怎么把论文喂给AI” |
| 输入 | 检索到的文档片段 | 原始PDF文件 |
| 输出 | 带引用的自然语言回答 | 结构化文本数据 |
| 类比 | 学生考试时如何答题 | 学生考试前如何整理笔记 |
技术挑战:大模型为什么“看不懂”PDF?
核心问题在于技术原理的差异:大语言模型主要处理和理解文本序列,而非直接解析视觉信息。当输入可的PDF时,模型可以直接获取文本流;但当输入扫描件PDF时,模型接收的实际上是一系列图像数据,缺乏可处理的文本信息-69。
具体技术挑战包括:
格式多样性:文档包含从TXT到复杂PDF的多种格式
内容复杂性:表格、公式、图表标题在简单文本提取中容易丢失-69
识别准确率低:模糊扫描、多语言混合会导致OCR错误率显著上升
结构还原性差:即便文字识别正确,如果阅读顺序和逻辑结构没被还原,提取出的信息也是混乱的-69
四、概念关系与区别总结
将上述概念梳理为一张逻辑图谱:
┌─────────────────────────────────────────────────────────────┐ │ 阅读论文AI助手(应用层) │ ├─────────────────────────────────────────────────────────────┤ │ ┌─────────────────────┐ ┌─────────────────────────┐ │ │ │ RAG(核心架构) │ ──依赖──▶ │ PDF文档解析(前置模块) │ │ │ │ “怎么回答” │ │ “怎么输入” │ │ │ └─────────────────────┘ └─────────────────────────┘ │ │ │ │ ┌─────────────────────┐ │ │ │ 大语言模型(LLM) │ │ │ │ “谁在回答” │ │ │ └─────────────────────┘ │ └─────────────────────────────────────────────────────────────┘
一句话总结:PDF文档解析决定了AI“看到什么”,RAG决定了AI“如何回答”,两者配合构成了阅读论文AI助手的技术地基。
五、代码示例:极简RAG论文问答系统
下面通过一个极简示例,直观展示阅读论文AI助手的核心工作流程。
极简RAG论文问答系统 - 模拟核心流程 import hashlib ========== 步骤1:准备论文摘要库(模拟PDF解析后的结果)========== papers_db = [ { "id": "paper_001", "title": "RAG技术综述", "abstract": "RAG结合检索与生成,提升大模型的事实准确性和可追溯性" }, { "id": "paper_002", "title": "PDF文档解析研究", "abstract": "复杂PDF中的表格和公式提取是RAG落地的关键瓶颈" }, { "id": "paper_003", "title": "大模型幻觉问题", "abstract": "大语言模型在专业领域常产生事实性偏差,RAG可有效缓解" } ] ========== 步骤2:检索函数(语义匹配的简化版)========== def retrieve(query, papers): """根据关键词检索相关论文片段""" query_keywords = set(query.lower().split()) results = [] for paper in papers: 计算关键词重叠度作为相关性评分 abstract_words = set(paper["abstract"].lower().split()) score = len(query_keywords & abstract_words) if score > 0: results.append({"paper": paper, "score": score}) 按相关性排序,取Top-2 results.sort(key=lambda x: x["score"], reverse=True) return [r["paper"] for r in results[:2]] ========== 步骤3:生成函数(模拟大模型回答)========== def generate(query, retrieved_papers): """基于检索到的论文片段生成回答""" if not retrieved_papers: return "抱歉,未找到相关论文信息。" 构建上下文(模拟RAG的增强阶段) context = "\n".join([f"- {p['title']}: {p['abstract']}" for p in retrieved_papers]) 模拟LLM生成(实际场景中调用OpenAI API或本地模型) 注意:这一步会基于context来生成答案,确保有据可查 answer = f"根据检索到的相关论文:\n{context}\n\n回答:{query} 涉及检索增强生成(RAG)技术,它通过引入外部知识检索来增强大模型的回答准确性。" return answer ========== 步骤4:RAG问答主流程 ========== def ask_question(query): """RAG问答入口""" print(f"用户提问:{query}") 步骤4.1:检索 retrieved = retrieve(query, papers_db) print(f"检索到 {len(retrieved)} 篇相关论文") 步骤4.2:增强 + 生成 answer = generate(query, retrieved) print(f"AI回答:{answer}") return answer 测试运行 if __name__ == "__main__": ask_question("什么是RAG技术?")
执行流程解读:
检索阶段:系统根据用户问题,在论文库中匹配最相关的文档片段
增强阶段:将检索到的片段拼接到提示词中,形成“上下文”
生成阶段:大模型基于上下文生成答案(本例中用模拟函数替代)
核心要点:答案中的所有信息都来自检索到的论文片段,而非模型凭空编造。这正是RAG区别于纯生成模型的关键所在。
六、底层原理:RAG的技术支撑
技术支撑一:向量检索与语义匹配
RAG检索的核心是向量数据库。原理如下:
将论文的每个段落通过嵌入模型转换为高维向量
用户提问时,将问题也转换为同维度的向量
通过余弦相似度等算法,在向量空间中查找最接近的问题向量所对应的文档片段
技术支撑二:文本分块策略
一篇论文动辄数十页,无法全部塞入大模型的上下文窗口。因此需要将论文切分成多个“块”(chunk)。研究表明,元数据增强和层次感知的分块策略对检索准确性的贡献,甚至超过了解析框架本身的选择-70。这意味着——如何切分论文,比用什么工具切分更重要。
技术支撑三:PDF文档解析的深度技术
对于扫描件论文,需要借助OCR(Optical Character Recognition,光学字符识别)技术将图像转换为文字。更进阶的方案采用多模态深度学习模型进行版面分析,智能识别标题层级、段落结构、表格合并关系等,实现结构与内容的双重还原-69。
技术定位
以上底层技术构成了阅读论文AI助手的基础设施,但源码级别的深入解析超出本文范围。后续将推出专门的进阶篇,逐一拆解这些技术细节,敬请期待。
七、2026年主流阅读论文AI助手推荐
⚠️ 以下推荐基于2026年4月的市场调研,工具价格和功能可能发生变化,请以官方信息为准。
快速决策指南
| 场景 | 推荐工具 | 核心优势 | 免费/价格 |
|---|---|---|---|
| 日常学术 | Perplexity AI | 带引用答案,支持网络 | 学生可免费使用Pro版12个月 |
| 深度文档分析 | Google NotebookLM | 基于上传文档回答,音频概览功能 | 完全免费 |
| PDF快速问答 | ChatPDF | 无需注册,界面简洁 | 基础功能免费 |
| 文献综述 | SciSpace | 语义+引用网络 | 免费试用后约$20/月 |
| 开源私有化 | SurfSense | 数据自主可控,支持本地部署 | 开源免费 |
各工具详解
Perplexity AI:2026年最佳免费学生研究助手。通过SheerID验证学生身份后,可免费获得12个月Pro访问权限,价值240美元。提供带引用的答案,支持使用GPT-5.2和Claude Sonnet 4.5进行无限-13。
Google NotebookLM:不网络,而是深度分析你上传的文档。仅根据你上传的内容回答问题,杜绝凭空编造事实。最独特的功能是音频概览——生成播客风格的讨论,两个AI声音像主持学习小组一样讲解你的文档-13。
ChatPDF:最知名的PDF问答工具之一,月访问量约260万次,用户无需注册即可使用基础功能-。
SurfSense:NotebookLM的开源平替,GitHub上已获得11K+ Star。支持私有化部署,数据完全掌握在自己手中。核心功能包括多模态RAG、AI播客生成、100+种大模型和6000+种嵌入模型的支持-33。
八、高频面试题与参考答案
面试题1:RAG是什么?它与纯大模型生成有什么区别?
参考答案:
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与大语言模型生成能力的技术架构。
区别如下:
数据来源:纯大模型仅依赖训练数据(有知识截止日期),RAG可从外部知识库实时检索
可追溯性:纯大模型无法追溯答案来源,RAG的答案基于检索到的文档,可提供引用
幻觉问题:纯大模型在专业领域容易产生事实性偏差,RAG通过检索约束显著缓解
时效性:纯大模型知识更新需要重新训练,RAG只需更新知识库
踩分点:定义全称 + 三个核心环节(检索→增强→生成)+ 至少两个对比维度。
面试题2:如何设计一个可扩展的文档解析架构,支持PDF、Word等多种格式?
参考答案:
设计思路是策略模式 + 工厂模式。
核心设计:
定义统一的
DocumentParser接口,包含parse(file) → StructuredData方法为每种格式实现具体的解析器:
PDFParser、WordParser、ExcelParser等使用
ParserFactory根据文件扩展名返回对应解析器实例若需新增Markdown格式,只需实现
MarkdownParser并注册到工厂,无需修改现有代码
关键点:解析器的输出格式统一(如JSON/Markdown),确保后续RAG流程不受格式变更影响。
面试题3:扫描件PDF为什么会导致大模型回答不准确?如何解决?
参考答案:
原因:大模型主要处理文本序列而非视觉信息。扫描件PDF本质是图像数据,缺乏可处理的文本信息。若不经过解析直接输入,模型无法获取实际内容-69。
解决方案:
前置OCR:使用光学字符识别将图像转换为文本
版面分析:运用多模态模型识别标题层级、段落结构、表格合并关系
格式统一:将解析结果转换为结构化格式(如Markdown),保留逻辑层次
元数据增强:补充标题、作者、章节等元信息,提升检索质量-70
面试题4:在构建论文问答系统时,如何确保AI引用的真实性?
参考答案:
技术层面:
采用RAG架构而非纯生成模型,确保答案基于检索到的文档片段
检索时保留来源ID和段落位置信息
生成答案时强制要求模型输出引用标注
架构层面:
构建高质量PDF解析管道,确保提取内容准确
使用分层分块策略,保留文档的逻辑结构
对扫描件文档采用专业OCR与版面分析
验证机制:提供“来源重点显示”功能,让用户点击引用即可跳转至原文对应段落,实现“信任但验证”-53。
九、结尾总结
本文围绕阅读论文AI助手,沿着“痛点 → 概念 → 关系 → 示例 → 原理 → 考点”的完整链路,系统梳理了以下核心知识点:
| 模块 | 核心要点 |
|---|---|
| 技术核心 | RAG = 检索 + 增强 + 生成,让AI回答有据可查 |
| 技术瓶颈 | PDF文档解析是RAG落地的前置关键 |
| 底层支撑 | 向量检索 + 文本分块 + OCR/版面分析 |
| 工具推荐 | Perplexity()、NotebookLM(深度分析)、ChatPDF(快速问答) |
重点与易错点提醒:
RAG≠纯大模型生成,区别在于是否检索外部知识
PDF解析≠简单文本提取,复杂表格和公式是常见坑点
2026年的趋势是从“单篇阅读”转向“水平综述”——利用AI同时分析数百篇论文,比较不同来源的主题与方法论-53
预告:后续将推出进阶篇,深入拆解向量检索、分块策略优化、GraphRAG图检索等进阶技术,并附送2026年最新论文问答系统的完整搭建代码。欢迎持续关注!