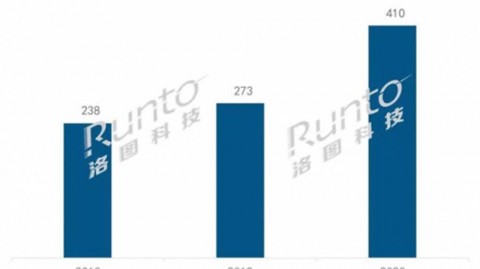
本文简介:2026年,直播电商市场规模已突破4.9万亿元,AI助手和直播智能体正成为这一万亿级产业的核心基础设施-1。本文从技术原理到代码实现,系统解析AI Agent的三大核心支柱与AI数字人直播的四大技术突破,面向开发者、面试备考者与技术入门学习者,兼顾易懂性与实用性,助你建立完整的知识链路。
一、痛点切入:为什么我们需要“助手直播AI”

1.1 传统直播运营的困境
传统直播场景下,商家面临一系列运营难题:用户进入直播间后缺乏个性化引导,转化率低下;用户询问得不到及时回应,潜在订单白白流失;多次浏览的“犹豫客”缺乏有效的智能助手辅助决策;播后复盘数据堆积如山,运营手动翻表到深夜却找不到优化方向-1。

从技术视角来看,传统解决方案存在以下三大短板:
人肉值守成本高:真人主播无法7×24小时在线,夜间黄金流量时段大量流失
响应滞后与信息不对称:弹幕提问无法得到即时、精准的标准化回复,大量订单在等待中流失
数据无法闭环:播后数据依赖人工统计,无法形成从数据洞察到运营优化的自动化闭环
1.2 为什么传统“无人直播”走不通了
更关键的是,各大主流直播平台的算法已能精准识别非实时互动的直播间。传统的循环播放式无人直播,因互动缺失、画面机械重复,极易触发平台风控机制,轻则限流,重则永久封号-4。
传统方案的致命缺陷:只有“播”的能力,没有“听”和“答”的能力。
正是这些痛点,催生了“助手直播AI”这一全新形态——它不是简单的播放器,而是一套基于大语言模型和实时渲染引擎的智能体系统-4。
二、核心概念讲解:AI Agent(AI智能体)
2.1 定义拆解
AI Agent(Artificial Intelligence Agent,人工智能智能体) 是一种具备自主感知、规划决策、工具调用与闭环执行能力的智能系统,而不仅是一个算法或模型-27。
从技术视角看,AI Agent的核心理念可以拆解为三个关键词:
自主性:Agent无需人工逐条指令驱动,可自主理解任务目标并规划执行路径
反应性:Agent能感知环境变化(如直播间弹幕、用户行为信号),并做出实时响应
主动性:Agent不仅是“被动应答”,还能主动识别机会(如用户多次浏览犹豫)并主动介入
2.2 生活化类比
把AI Agent理解为一个人类员工会更直观。它需要具备以下能力:理解任务、记住上下文、调用工具、规划步骤、执行落地-13。技术专家将AI Agent模拟成人类员工来阐释其工作原理:它需要“大脑”来思考规划,“眼睛耳朵”来感知信息,“手脚”来操作执行,“记忆”来积累经验-13。
2.3 作用与价值
AI Agent的价值在于将大模型的“认知能力”转化为“执行能力” 。它融合了大模型的认知力与系统执行力,推动软件从人工驱动走向策略驱动,实现从“能说”到“能干”的跃迁-27-13。
三、关联概念讲解:AI数字人(AI Digital Human)
3.1 定义
AI Digital Human(AI数字人) 是指基于多模态大模型与AIGC技术生成或驱动的、具备自然交互能力的虚拟形象系统-2。
与早期的“3D模型+语音合成”不同,2026年的AI数字人技术已进入“多模态+大模型”深度融合的新阶段——基于百亿参数级的大语言模型(如Qwen、DeepSeek、Kimi等),数字人具备更强的语义理解、上下文记忆、逻辑推理和知识调用能力-2。
3.2 AI Agent与AI数字人的关系
这两个概念常被混用,但它们的逻辑关系非常清晰:
| 维度 | AI Agent | AI数字人 |
|---|---|---|
| 本质 | 智能系统/能力架构 | 交互界面/呈现形态 |
| 侧重 | 思考、规划、执行 | 感知、表达、交互 |
| 类比 | 大脑+神经系统 | 身体+五官 |
| 关键组件 | Planner、Memory、Tool Use | 多模态感知、AIGC生成、动作表情 |
一句话概括:AI Agent是数字人的“大脑”,数字人是AI Agent的“身体”。一个完整的智能直播助手,需要两者的深度融合——Agent负责“想什么、怎么做”,数字人负责“怎么说、怎么演”。
四、底层原理:AI Agent的三大技术支柱
4.1 支柱一:记忆管理
AI Agent的记忆分为两层-13:
工作记忆(Working Memory) :相当于人类的工作台,存放当前正在处理的任务信息。面临上下文窗口有限的挑战,行业主流采用长文本摘要、轻量化记忆压缩方案来优化存储。
外部记忆(External Memory) :相当于智能体的“硬盘”,通过向量数据库实现语义相似度检索,或使用知识图谱将实体关系组织起来,支持多跳推理。
面试要点:Agent记忆不是简单的“长上下文”,而是“工作记忆+长期记忆”的两级架构,配合遗忘策略实现可持续运行。
4.2 支柱二:工具学习
AI Agent不只是一个语言模型,它需要真正“做事”。工具学习包含三阶段框架-13:
工具发现:Agent能感知自己有哪些可用工具(依赖良好的工具注册和描述机制)
工具选择:给定任务,Agent能选出最合适的工具组合(考验模型的任务理解能力)
工具对齐:Agent知道怎么正确调用工具,参数怎么填,返回结果怎么用
2026年值得关注的新协议是 MCP(Model Context Protocol,模型上下文协议) ,由Anthropic主导,可理解为AI模型的“USB接口”——任何支持MCP的AI客户端都能插上各种工具和数据源-13。
4.3 支柱三:规划推理
AI Agent通过“感知 → 规划 → 执行 → 反馈”的闭环结构,实现目标驱动的自主决策与持续运行-27。这一闭环机制使Agent区别于传统的“模型调用”模式——它具备持续运行和自我调整的能力,能够从执行结果中学习并修正策略-27。
五、代码/流程示例演示
5.1 极简Agent框架示例(Python伪代码)
以下示例展示一个直播间智能客服Agent的核心逻辑框架:
极简Agent框架示例:直播间智能客服 class LiveStreamAgent: def __init__(self): self.llm = LLMClient() 大语言模型(决策核心) self.memory = VectorMemory() 向量记忆(存储历史) self.tools = ToolRegistry() 工具注册表 self.register_tools() def register_tools(self): """注册可用工具""" self.tools.add("query_product_db", self.query_product) self.tools.add("send_reply", self.send_to_chat) self.tools.add("get_user_profile", self.get_profile) def perceive(self, environment): """感知:接收弹幕、用户行为等输入""" return { "messages": environment.get_messages(), "user_actions": environment.get_behavior() } def plan(self, goal, context): """规划:将目标拆解为可执行任务""" 利用LLM进行任务拆解,结合历史记忆 plan = self.llm.plan(goal, context, self.tools.list()) return plan def execute(self, plan): """执行:调用工具完成具体操作""" for step in plan: tool = self.tools.get(step["tool_name"]) result = tool.execute(step["params"]) return result def feedback(self, result): """反馈:根据结果修正策略""" self.memory.store(result) 存入记忆,用于后续优化 return self.adjust_strategy(result) def run(self, environment, goal): """完整Agent闭环""" context = self.perceive(environment) plan = self.plan(goal, context) result = self.execute(plan) self.feedback(result) return result
5.2 新旧对比:传统方案 vs Agent方案
| 对比维度 | 传统脚本驱动 | AI Agent驱动 |
|---|---|---|
| 问答响应 | 预设话术匹配,无法应对新问题 | 大模型实时生成,理解语义后回答 |
| 话术调整 | 固定脚本,无法动态优化 | 根据实时数据(点击率、转化率)动态调整 |
| 记忆能力 | 无记忆,每次对话独立 | 向量记忆,长期积累用户画像 |
| 风控合规 | 机械重复易触发平台封禁 | 生成画面帧率、声音波形符合真人直播特征 |
六、AI数字人直播的四大技术突破
结合行业最新发展,AI数字人直播的底层支撑来自以下四大技术突破:
6.1 多模态融合能力
数字人不再局限于语音或文本单向输出,而是能同步理解并生成语音、表情、肢体动作、眼神、手势等多通道信号,实现类人自然交互-2。
6.2 大模型驱动智能内核
基于百亿参数级的大语言模型(如Qwen、DeepSeek、Kimi等),数字人具备更强的语义理解、上下文记忆、逻辑推理和知识调用能力-2。
6.3 微调与RAG并行
2026年趋势:对固定知识领域(如产品FAQ),企业更倾向使用有监督微调(SFT) 将知识压缩进模型参数,降低部署成本;对动态信息(如实时价格、库存),则采用RAG(检索增强生成) 实时从向量数据库检索最新信息,形成“开卷式作答”-2。
6.4 实时交互与动态话术
智享AI直播三代系统具备自我学习能力,能根据直播间的实时数据(如点击率、转化率、用户情绪)动态调整话术策略。当发现用户对价格敏感时,AI会自动切换至“性价比强调”模式;当流量高峰期到来时,则自动启动“逼单促单”逻辑-4。
七、高频面试题与参考答案
Q1:什么是AI Agent?它与大模型有什么区别?
参考答案(踩分点:定义 + 能力边界 + 系统形态):
AI Agent是一种具备自主感知、规划决策、工具调用与闭环执行能力的智能系统。与大模型的本质区别在于:大模型是“能力提供者”,擅长理解、生成和推理,但本身不具备目标意识和执行能力;AI Agent是“系统形态”,以模型为核心决策单元,叠加规划、执行和状态管理能力,关注“如何完成目标”-27。简单说,大模型解决“怎么想”,Agent解决“怎么干”。
Q2:AI Agent的核心技术组件有哪些?
参考答案:一个可落地的AI Agent系统通常由四大模块构成-27:
大语言模型作为决策核心,负责理解目标并生成决策建议
任务分解与规划机制将复杂目标拆解为多个可执行子任务
工具调用接口通过Tool/Function Calling操作真实系统
状态管理与长期记忆记录上下文、历史决策和执行结果
Q3:什么是RAG?它在企业级AI中扮演什么角色?
参考答案:RAG(Retrieval-Augmented Generation,检索增强生成)是一种将信息检索与生成模型相结合的技术框架。在2026年的企业级应用中,RAG已从简单的“检索-生成”管道演变为成熟的知识运行时系统——包含多级索引、重排序机制以及知识图谱增强的复合架构,核心目标是确保输出信息具备可追溯性,有效降低大模型幻觉风险-51。
Q4:Agentic AI与传统Copilot模式有何本质不同?
参考答案:Copilot是辅助模式——用户下达指令,AI提供建议,最终决策和执行仍由人完成;Agentic AI是自主执行模式——AI能够独立规划、调用工具、完成全流程任务-12。在YC W26批次的198家公司中,有56家正在研发全自主Agent,Copilot时代仅维持了约18个月便宣告落幕-12。
Q5:多模态技术对AI数字人直播有何意义?
参考答案:多模态技术使AI数字人能够同步理解并生成语音、表情、肢体动作、眼神、手势等多通道信号,实现类人自然交互-2。在直播场景中,这意味着数字人能够:① 实时识别弹幕语义并做出表情回应;② 根据商品类型自动匹配展示动作;③ 感知用户情绪调整话术策略-2-4。
八、结尾总结与展望
8.1 核心知识点回顾
| 序号 | 核心知识点 | 一句话记忆 |
|---|---|---|
| ① | AI Agent | 能思考、能规划的智能系统,而非仅能对话的模型 |
| ② | 记忆管理 | 工作记忆(台面)+ 外部记忆(硬盘)= 持续智能 |
| ③ | 工具调用 | 三阶段:发现工具 → 选择工具 → 对齐调用 |
| ④ | 规划闭环 | 感知→规划→执行→反馈,而非单次问答 |
| ⑤ | 数字人 | Agent的大脑 + 数字人的身体 = 完整交互体验 |
8.2 关键结论
2026年是AI Agent的爆发元年,技术条件(推理模型成熟、工具生态完善、成本大幅下降)已同时具备-11
Agent ≠ 大模型,前者是系统形态,后者是能力组件
RAG是企业级AI落地的核心基础设施,用于解决大模型的“幻觉”问题和知识时效性瓶颈
8.3 进阶预告
下一篇我们将深入 MCP协议 和 AgentOps(智能体运营体系) 的工程化落地实践,包括多智能体协作、Agent行为治理框架以及生产环境部署的最佳实践。
🔗 参考资料
诺云:直播 AI 全链路 agent 矩阵-1
2026 AI数字人技术与应用深度解析-2
2026直播行业观察:智享AI直播三代-4
AI Agent系统架构与工程化演进-27
2026年智能体(Agent)爆发年-11